Enforcing AWS Resource Tags with OPA
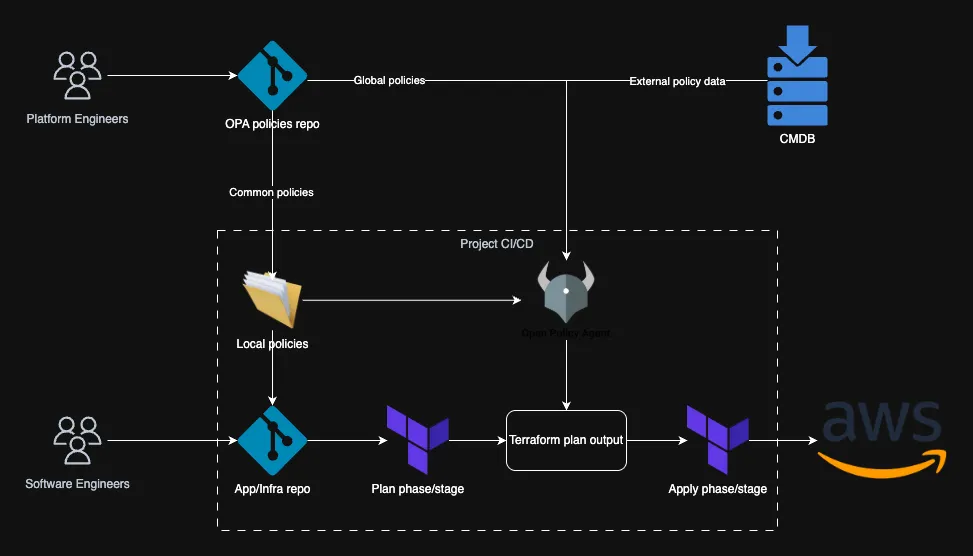
In Part 1 of this series, we covered the basics of Policy as Code and how the shift-left approach helps catch infrastructure mistakes early. In this post, we’re putting theory into practice—specifically, how to enforce AWS tagging strategy using Open Policy Agent (OPA) during Terraform plan phase/stage.
This isn’t just about tagging hygiene. Good tagging is foundational for tracking cloud costs, understanding ownership, and avoiding dangerous or expensive mistakes.
Why Tags Matter
Tags seem trivial—until you’re staring at a $1M AWS bill and have no idea where it came from.
Tags let you break down your cloud spend by project, team, environment, or business unit. They also help tools like AWS Cost Explorer, Budgets, and third-party dashboards make sense of your usage.
But tagging is more than accounting. When used well, tags answer:
Who created this resource?
What is it for?
When was it changed?
Where is the code?
Automation based on tags
Reports based on tags
One tag that I strongly recommend, by simply adding:
REPO = "<https://your git server/org/project>"
This one line tells you the exact repo that created the resource—giving instant access to Git blame, commit history, and ownership. It’s the ultimate breadcrumb.
Common Mistake: Forgetting to Tag
It happens. A dev spins up a quick EC2 instance or Lambda for a side task and forgets to tag it. A week later, it’s costing money, no one knows why it’s there, and no one dares delete it.
Automating tag creation through CI/CD pipelines can simplify the process and ensure consistency. For instance, tags like REPO can be automatically added during deployment. However, cost-related tags often require more context, such as project or team ownership, which may not be easily inferred by automation. These tags typically depend on organizational processes and workflows, requiring developers or infrastructure engineers to provide them as input during resource creation or deployment.
That’s where OPA + Terraform plan comes in.
The implementation
To implement our tagging policy, we use external data files in JSON format to define the required tags and their values. These files specify two types of tags: common tags that are enforced across all environments and environment-specific tags tailored to the current environment. This approach ensures flexibility and consistency, allowing us to adapt tagging requirements based on organizational needs while maintaining a standardized tagging structure across deployments.
import data.required_tags_policy
import data.common_required_tags_policy
required_tags = common_required_tags_policy.common_required_tags {
not required_tags_policy.required_tags
} else = array.concat(common_required_tags_policy.common_required_tags, required_tags_policy.required_tags)
required_tags_values = common_required_tags_policy.common_required_tags_values {
not required_tags_policy.required_tags_values
} else = object.union(common_required_tags_policy.common_required_tags_values, required_tags_policy.required_tags_values)
To further refine our tagging strategy, we introduce a third external data concept: a list of resources that are whitelisted. These resources may fall into one of the following categories:
Resources that do not support tags: Some AWS resources inherently lack tagging capabilities, making it impractical to enforce tagging policies for them.
Resources with zero cost: Certain resources may not incur any charges, and tagging them might not provide meaningful insights into cost allocation.
Excluded resources: In some cases, specific resources may be intentionally excluded from the tagging strategy due to organizational decisions or unique use cases.
resource_whitelist = common_required_tags_policy.common_resource_whitelist {
not required_tags_policy.resource_whitelist
} else = array.concat(common_required_tags_policy.common_resource_whitelist, required_tags_policy.resource_whitelist)
Additionally, our implementation ensures that tags are validated not only from the AWS resource/module definitions but also from default tags defined in the Terraform provider section. This comprehensive approach guarantees that all tags—whether explicitly declared or inherited from provider-level defaults—adhere to the established tagging policy. By doing so, we minimize the risk of missing critical tags and maintain consistency across all resources in the deployment.
get_tags(resource) = tags {
tags := merge_objects(resource.change.after.tags_all, resource.change.after.tags)
} else = empty {
empty = {}
}
By decoupling external data from the policy repository, organizations can maintain a clean separation of concerns. All external data files, such as required tags, tag values, and resource whitelists, can be stored in a separate repository. This approach simplifies policy management and allows external data to be dynamically generated during CI/CD pipelines.
For example, external data can be autogenerated on the fly by hitting an API, querying a database, or using other mechanisms to fetch the latest organizational requirements. This ensures that policies always operate on up-to-date data without requiring manual updates to the policy repository. By integrating this process into CI/CD workflows, organizations can achieve a high degree of automation and flexibility in enforcing tagging policies.
Everything together
Here is the complete policy that evaluates AWS resource tags and their corresponding values. It ensures that all required tags are present and validates their values against predefined rules. By leveraging this policy, organizations can enforce consistent tagging practices, reduce cloud waste, and improve resource traceability.
package required_tags
# Enforces a set of required tag keys. Values are both checked
import input as tfplan
import data.required_tags_policy
import data.common_required_tags_policy
required_tags = common_required_tags_policy.common_required_tags {
not required_tags_policy.required_tags
} else = array.concat(common_required_tags_policy.common_required_tags, required_tags_policy.required_tags)
resource_whitelist = common_required_tags_policy.common_resource_whitelist {
not required_tags_policy.resource_whitelist
} else = array.concat(common_required_tags_policy.common_resource_whitelist, required_tags_policy.resource_whitelist)
required_tags_values = common_required_tags_policy.common_required_tags_values {
not required_tags_policy.required_tags_values
} else = object.union(common_required_tags_policy.common_required_tags_values, required_tags_policy.required_tags_values)
# required_tags_values = required_tags_policy.required_tags_values
array_contains(arr, elem) {
arr[_] = elem
}
evaluated_resources[r] {
r := tfplan.resource_changes[_]
not array_contains(resource_whitelist, r.type)
}
has_key(x, k) {
_ = x[k]
}
pick_first(k, a, b) = a[k] {
k := {k | some k; _ = a[k]}
} else = b[k]
merge_objects(a, b) = c {
ks := {k | some k; _ = a[k]} | {k | some k; _ = b[k]}
c := {k: v | k = ks[k]; v := pick_first(k, b, a)}
}
get_tags(resource) = tags {
tags := merge_objects(resource.change.after.tags_all, resource.change.after.tags)
} else = empty {
empty = {}
}
deny[reason] {
resource := evaluated_resources[_]
action := resource.change.actions[count(resource.change.actions) - 1]
array_contains(["create", "update"], action)
tags := get_tags(resource)
# creates an array of the existing tag keys
existing_tags := [key | tags[key]]
required_tag := required_tags[_]
not array_contains(existing_tags, required_tag)
reason := sprintf(
"%s: missing required tag %q",
[resource.address, required_tag]
)
}
deny[reason] {
resource := evaluated_resources[_]
action := resource.change.actions[count(resource.change.actions) - 1]
array_contains(["create", "update"], action)
tags := get_tags(resource)
required_tag := [key | required_tags_values[key]][_]
not array_contains(required_tags_values[required_tag], tags[required_tag])
reason := sprintf(
"%s: has tag {%s = %s} Allowed values are %v",
[resource.address, required_tag, tags[required_tag], required_tags_values[required_tag]]
)
}
To evaluate the policy against the Terraform plan output, as I mentioned in the previous blog post I’m going to use conftest as preferred tool, but you can evaluate the policy against plan output using and opa cli. Here’s how you can do it:
# <get or generate the input data for OPA policy evaluation >
terraform plan -out=tfplan.binary
terraform show -json tfplan.binary > tfplan.json
conftest test tfplan.json -p <path to your policy> -p <path to your policies folder> -d <path to input data COMMON> -d <path to input data SPECIFIC>
You can use the
conftest test --update <policy repo url>command to directly fetch and apply policies from a remote repository. This approach can be useful for ensuring that you are always using the latest policies without manually updating them. For more information, refer to the official documentation: https://www.conftest.dev/sharing/.
However, based on practical experience, this method can be more challenging to debug and test, especially in scenarios where there are restricted access permissions between repositories. Due to these limitations, it may be preferable to handle policy updates as part of an external process, ensuring better control and visibility over the policies being applied.
This sequence of commands will:
- Go get or generate the external data for the policy, it could be simple
git clone <the repo containing the JSON files>or some bash/python script hitting company’s Configuration Management Database (CMDB) to get the data for the specific project, etc.- As I mentioned the policies can be in separate repository and at this first step we should clone it.
- Generate a Terraform plan and save it as a binary file (
tfplan.binary). - Convert the binary plan file into a JSON format (
tfplan.json). - Use
conftestto test the JSON plan against the defined OPA policies.
Conclusion
By adopting Open Policy Agent (OPA) and the shift-left paradigm, organizations can significantly enhance their cloud governance and operational efficiency. Here are the key benefits:
Proactive Issue Detection: By integrating policy checks early in the development lifecycle, potential misconfigurations, such as missing or incorrect tags, are identified before deployment. This reduces the risk of costly mistakes and ensures compliance with organizational standards.
Improved Cost Management: Enforcing tagging policies helps track cloud expenses effectively, enabling better cost allocation and accountability. Tags provide visibility into resource ownership, purpose, and usage, which are critical for optimizing cloud spend.
Enhanced Automation: Automating policy enforcement through CI/CD pipelines ensures consistency and reduces manual effort. This approach minimizes human error and accelerates the deployment process while maintaining compliance.
Scalability and Flexibility: The use of external data files for policy definitions allows organizations to adapt quickly to changing requirements. Policies can be updated dynamically without modifying the core policy logic, ensuring scalability across diverse environments.
Improved Resource Traceability: Tags like
REPOprovide direct links to the source code repository, enabling quick identification of resource ownership and history. This traceability simplifies debugging, auditing, and collaboration across teams.Compliance and Governance: OPA’s robust policy framework ensures adherence to organizational and regulatory standards. By enforcing consistent tagging practices, organizations can demonstrate compliance during audits and maintain a strong governance posture.
Reduced Cloud Waste: By identifying untagged or improperly tagged resources, organizations can eliminate unused or unnecessary resources, reducing cloud waste and optimizing resource utilization.
In summary, combining OPA with the shift-left paradigm empowers organizations to enforce robust tagging strategies, improve cloud governance, and achieve operational excellence. This approach not only enhances resource management but also fosters a culture of accountability and efficiency, enabling teams to build and deploy with confidence.